

【原报告在线阅读和下载】:20260617【MKList.com】算力芯片行业报告:大模型驱动算力变革,国产算力迎增量机遇 | 四海读报
【迅雷&夸克批量下载】:四海读报网研究报告网盘批量下载-资源清单社区-认知清单-四海清单
一、一句话核心观点
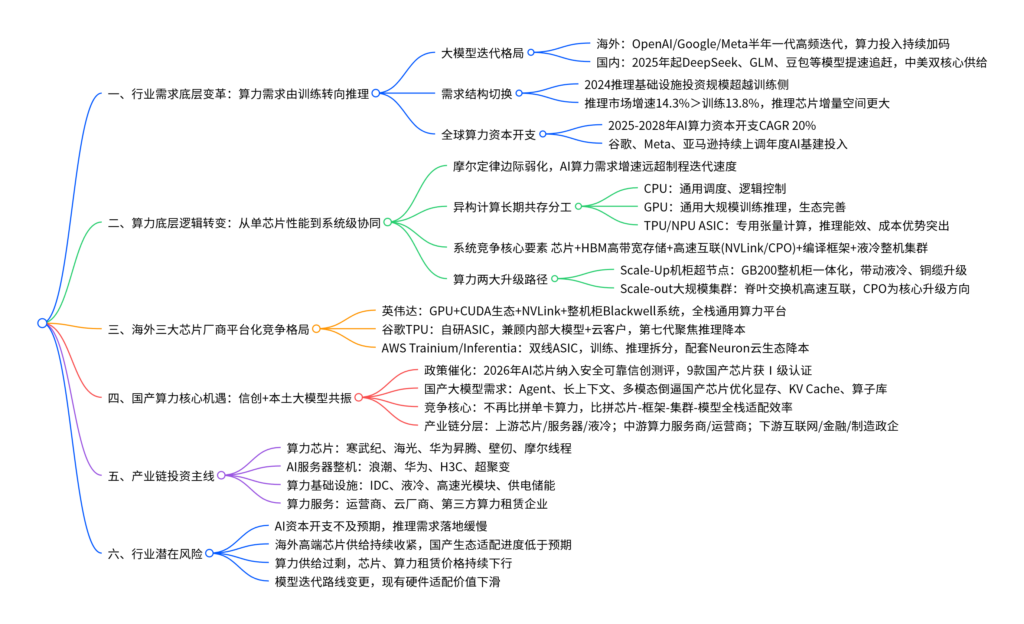
大模型持续迭代推动算力需求由训练侧向推理侧转移,行业竞争从单芯片峰值性能比拼转向芯片、软件、互联、集群一体化系统效率竞争,海外巨头依托完整软硬件平台构建壁垒,国内依托信创政策与国产大模型崛起实现算力芯片全栈国产替代,推理赛道、国产AI芯片、算力基础设施全产业链迎来长期增量机会。
二、全文思维导图
三、文档完整核心内容总结(表格+列表呈现)
(一)行业核心增长数据汇总表
1. 训练&推理算力市场增速对比
| 市场赛道 | 2024-2028年复合增速 | 核心需求特点 |
|---|---|---|
| AI推理算力市场 | 14.3% | 高并发、低延迟、控成本,下游MaaS、智能体放量拉动 |
| AI训练算力市场 | 13.8% | 大模型预训练、MoE模型迭代,资本开支增速放缓 |
2. 海外头部云厂商2026年AI资本开支预测
| 企业 | 2026年资本开支区间 | 核心投入方向 |
|---|---|---|
| 亚马逊 | 2000亿美元 | GPU服务器、海外算力集群、自研Trainium芯片产线 |
| 谷歌Alphabet | 1800-1900亿美元 | TPU集群、数据中心、Gemini模型配套算力 |
| Meta | 1250-1450亿美元 | AI超节点机柜、自研算力芯片、全球算力节点扩张 |
3. 全球AI算力资本开支规模(2023-2028)
| 年份 | 全球AI算力资本开支总额 | 同比增速 |
|---|---|---|
| 2023 | 2600亿美元 | 基数年份 |
| 2024 | 4350亿美元 | +67.3% |
| 2025 | 5930亿美元 | +36.3% |
| 2028预测 | 10220亿美元 | CAGR稳定20% |
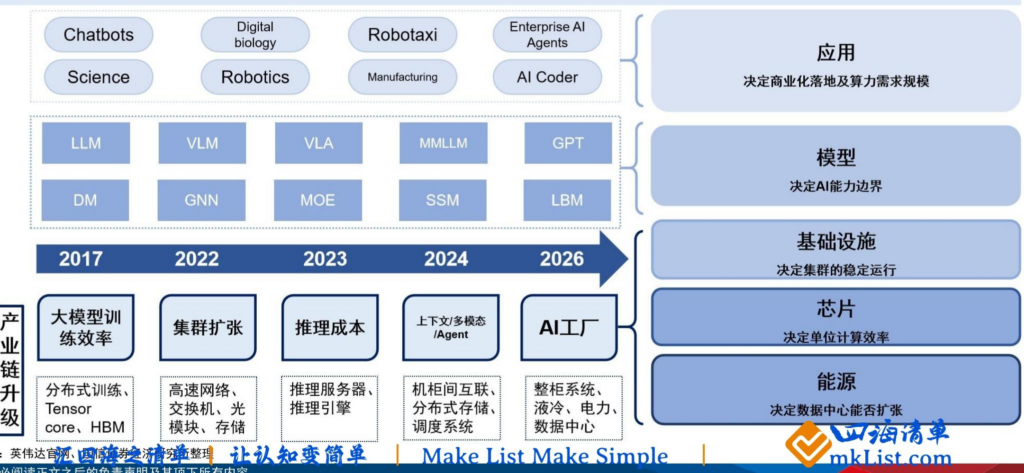
(二)AI五层产业蛋糕分层结构(自下而上)
- 能源层:决定数据中心算力扩容上限,包含供电、储能、液冷散热体系
- 芯片层:决定单位算力运行效率,GPU/NPU/TPU/CPU各类算力芯片
- 基础设施层:保障大规模集群稳定运行,AI服务器、交换机、整机柜超节点
- 模型层:定义AI算力能力边界,LLM、多模态、MoE、智能体Agent模型
- 应用层:决定算力市场规模天花板,办公、工业、自动驾驶、企业AI服务
(三)算力芯片架构分工对比表
| 芯片类型 | 核心定位 | 核心优势 | 短板 | 适配场景 |
|---|---|---|---|---|
| CPU | 通用调度中枢 | 逻辑处理灵活、生态通用 | 并行算力弱 | 集群调度、业务逻辑、基础通用计算 |
| GPU | 通用AI加速核心 | CUDA生态完善、兼顾训练+推理、可编程性强 | 单位算力成本偏高 | 通用大模型训练、多模态推理、全场景通用算力 |
| TPU/NPU ASIC | 专用张量加速器 | 推理能效高、单位算力成本低 | 通用性弱、生态适配成本高 | 大规模云端推理、边缘AI、固定架构模型降本 |
(四)海外三大厂商算力平台发展路线对比
1. 英伟达发展脉络
- 1999 GeForce:图形GPU起步;2006 CUDA发布开启通用并行计算
- A100:统一训练、推理、数据分析;H100强化Transformer引擎、FP8精度
- GB200 Blackwell:迈入机柜级超节点系统,竞争升级为芯片+网络+软件整机平台
- 核心壁垒:CUDA软件生态、NVLink高速互联、整机柜一体化交付能力
2. 谷歌TPU发展脉络
- TPU v1:内部推理专用ASIC;v2/v3拓展大规模训练集群
- TPU v4:面向超大规模基础模型;v5e/v5p区分性价比/高性能路线
- 第六代Trillium、第七代Ironwood:聚焦推理时代,优化多模态、Agent并发算力
- 核心定位:自有Gemini模型配套+谷歌云对外算力服务
3. AWS自研芯片双线布局
- 推理线:Inferentia系列,主打低成本低延迟云上推理
- 训练线:Trainium系列,Trainium3 UltraServer面向生成式AI、智能体训练
- 配套Neuron软件栈+SageMaker云平台,完整闭环降低客户算力综合成本
(五)国产算力政策与行业突破
-
核心政策利好
2026年5月,国家安全可靠测评新增独立AI芯片品类,9款国产芯片获评安全可靠Ⅰ级:华为海思、平头哥、海光信息、壁仞科技、摩尔线程等,国产算力正式纳入信创采购体系。 -
中美大模型供给格局(2025)
- 美国知名AI模型59个,中国35个,欧洲仅2个,中美为全球两大核心供给方
- 海外模型单模型训练算力密度显著高于国内,国产模型算力优化空间广阔
-
头部国产大模型算力适配需求表
厂商 代表模型 算力硬件核心适配要求 智谱AI GLM全系列 支持企业私有化部署、多用户并发、图文视频多模态长文本 MiniMax M3系列 超大显存、长上下文稳定推理、多步骤Agent工具调用 DeepSeek V3/R1/V4 高性价比训练推理、MoE专家并行、低显存占用优化
(六)算力芯片迭代完整发展阶段列表
- 1940-1970:CPU通用计算时代,以通用逻辑调度为核心
- 1999-2005:GPU图形并行计算萌芽,图形卡拓展并行算力
- 2006-2012:GPGPU平台化,CUDA生态诞生,GPU进入通用AI计算
- 2012-2017:深度学习专用GPU,Tensor Core、矩阵加速优化
- 2017-2020:云端ASIC/NPU落地,推理专用降本芯片量产
- 2024至今:大模型高密度算力集群,整机柜超节点、HBM、高速互联成为标配
(七)算力产业链上下游完整清单
上游(硬件供给端)
- 算力芯片:英伟达、AMD、华为昇腾、寒武纪、海光、壁仞、摩尔线程
- AI服务器:浪潮、华为、H3C、超聚变
- 配套基础设施:高速交换机/光模块、液冷设备、UPS、储能、机房温控
中游(算力服务端)
- 基础电信运营商:移动、电信、联通
- 云服务商:阿里云、华为云、火山引擎、腾讯云、百度智能云
- 第三方IDC/算力租赁:润泽、光环新网、数据港、奥飞数据、润建股份
下游(算力需求端)
- 互联网大厂:字节、阿里、腾讯、百度、京东
- 本土AI企业:DeepSeek、智谱、MiniMax、科大讯飞、月之暗面
- 行业客户:金融机构、政务、高端制造、自动驾驶企业
(八)行业核心风险汇总表
| 风险类型 | 具体影响 |
|---|---|
| AI资本开支不及预期 | 云厂商、互联网企业削减算力采购,推理芯片、IDC需求增速下滑 |
| 国产生态适配不及预期 | 国产芯片算子库、框架适配速度慢,信创落地进度延后 |
| 算力供给过剩风险 | 海内外厂商同步扩产芯片与服务器,算力租赁、芯片价格持续下行 |
| 技术路线迭代风险 | 大模型架构、算力底层技术快速革新,现有硬件投资贬值 |
| 海外供应链约束 | 高端HBM、先进制程设备供给受限,国产算力上限短期承压 |
© 版权声明
免费分享是一种美德,知识的价值在于传播;
本站发布的图文只为交流分享,源自网络的图片与文字内容,其版权归原作者及网站所有。
THE END










暂无评论内容