

【原报告在线阅读和下载】:20260514【MKList.com】电子行业专题报告:DeepSeek V4发布,国产算力乘风起航 | 四海读报
【迅雷&夸克批量下载】:四海读报网研究报告网盘批量下载-资源清单社区-认知清单-四海清单
1. 一段话总结
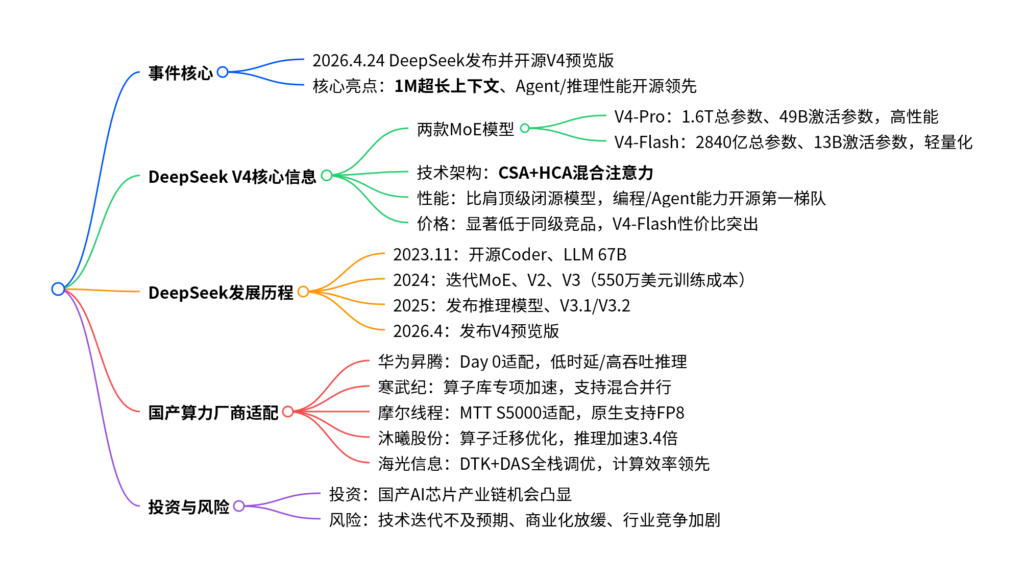
2026年4月24日DeepSeek发布并开源V4预览版,含V4-Pro(1.6万亿总参数)与V4-Flash(2840亿总参数)两款MoE模型,全系标配1M超长上下文,融合CSA与HCA混合注意力架构实现算力与显存大幅优化,性能比肩顶级闭源模型且价格优势显著;华为昇腾、寒武纪、摩尔线程、沐曦股份、海光信息等国产算力厂商均完成Day 0极速适配,芯模协同生态完善,带动国产算力产业链需求释放,同时存在技术、商业化、竞争三类风险。
2. 思维导图
3. 详细总结
一、DeepSeek V4发布核心事件
2026年4月24日,DeepSeek发布并同步开源V4预览版,核心突破为1M超长上下文能力,Agent交互、世界知识储备、推理性能位居开源大模型前列,为国产算力生态提供核心模型支撑。
二、DeepSeek发展历程
DeepSeek以开源+低成本为核心战略,迭代节奏高效:
- 2023年11月:首推开源代码模型DeepSeek Coder(性能超CodeLlama)、通用模型DeepSeek LLM 67B(对标LLaMA2 70B)。
- 2024年:发布国内首个开源MoE模型、V2模型;12月推出V3,训练成本仅550万美元,性能对标国际闭源模型,速度提升3倍。
- 2025年1月:发布推理模型R1-Zero/R1;8-12月迭代V3.1(支持Agent)、V3.2(预研百万级上下文)。
- 2026年4月:正式发布V4预览版并开源。
三、DeepSeek V4模型核心参数与架构
1. 两款MoE模型参数对比
| 模型 | 总参数 | 激活参数 | 预训练数据 | 上下文长度 | 核心定位 |
|---|---|---|---|---|---|
| V4-Pro | 1.6万亿 | 49B | 33T | 1M | 高性能研发,对标顶级闭源模型 |
| V4-Flash | 2840亿 | 13B | 32T | 1M | 轻量化部署,低成本高吞吐 |
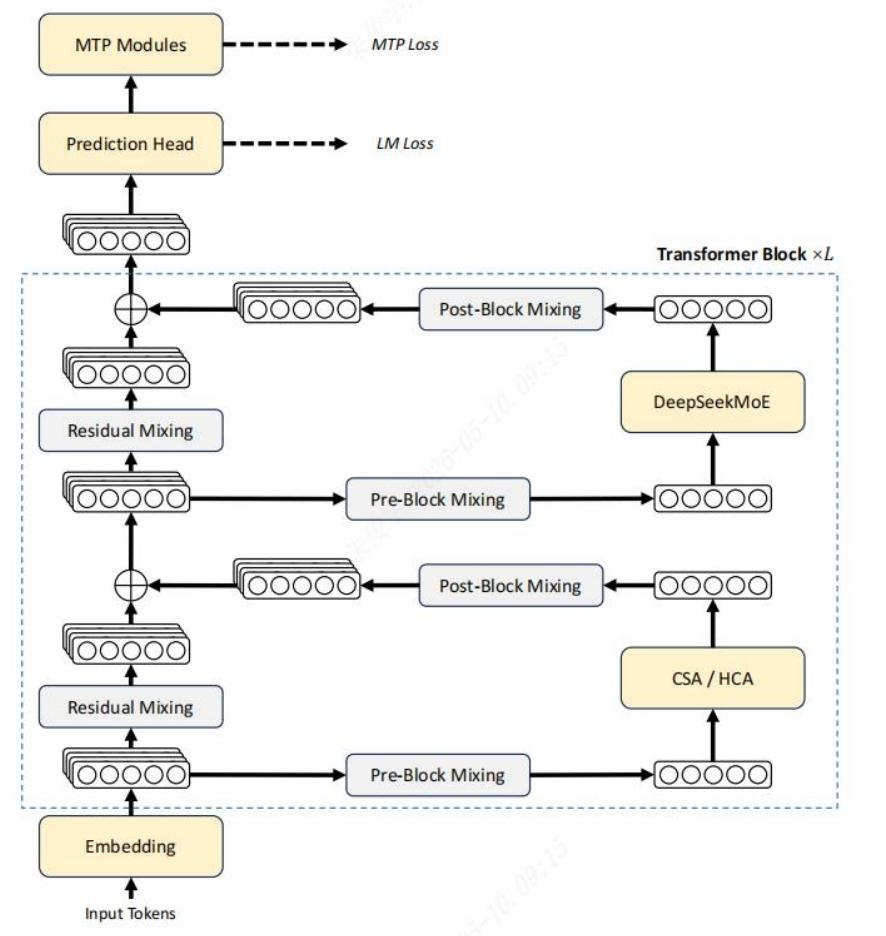
2. 技术架构创新
- 融合CSA(压缩稀疏注意力)+HCA(重度压缩注意力)混合架构,优化长上下文推理效率。
- 性能优化:1M上下文下,V4-Pro单Token计算量仅为V3.2的25%,KV缓存占用降至10%,首次将1M上下文设为全系标配。
3. 性能与价格优势
-
性能:V4-Pro综合能力比肩顶级闭源模型,Agent与编程能力开源第一梯队,世界知识储备领先同类。
-
价格(原价,2026.5.31前2.5折):
- V4-Pro:输入1.74美元/百万Tokens、输出3.48美元/百万Tokens,低于Claude Sonnet 4.6。
- V4-Flash:输入0.14美元/百万Tokens、输出0.28美元/百万Tokens,性价比突出。
四、国产算力厂商适配进展
DeepSeek V4实现NVIDIA GPU+华为昇腾NPU双平台适配,5家核心国产算力厂商完成Day 0极速适配:
- 华为昇腾:发布当日全系列适配,950 PR/DT系列实现10-20ms低时延推理,Atlas-A3系列实现30ms高吞吐推理。
- 寒武纪:自研算子库专项加速核心模块,vLLM框架支持混合并行,释放底层算力。
- 摩尔线程:MTT S5000完成全链路适配,原生支持FP8,适配V4“FP4+FP8”策略,显存带宽压力降50%。
- 沐曦股份:联合KernelSwift完成算子适配,国产芯片端推理加速3.4倍,适配周期大幅缩短。
- 海光信息:依托DTK异构平台+DAS系统,集成2000+算子,全栈调优实现领先计算效率。
五、投资建议与风险提示
-
投资建议:DeepSeek V4升级叠加国产算力快速适配,芯模协同生态完善,建议关注国产AI芯片产业链投资机会。
-
核心风险
- 技术风险:模型迭代、国产芯片适配进度不及预期。
- 商业化风险:行业应用渗透不足,落地节奏放缓。
- 竞争风险:全球厂商新品密集发布,价格下行压缩盈利空间。
4. 关键问题与答案
问题1:DeepSeek V4相较于前代及竞品,核心竞争优势体现在哪些方面?
答案:核心优势集中在三点:1. 技术性能:全系标配1M超长上下文,CSA+HCA架构使V4-Pro计算量、缓存占用仅为V3.2的25%、10%,性能比肩顶级闭源模型,编程/Agent能力开源第一梯队;2. 价格成本:V4-Pro价格显著低于同级Claude Sonnet 4.6,V4-Flash输入/输出仅0.14/0.28美元/百万Tokens,性价比行业领先;3. 国产适配:发布当日完成华为昇腾、寒武纪等5家国产算力厂商Day 0适配,芯模协同生态完善,适配效率远超前代模型。
问题2:寒武纪、摩尔线程、沐曦股份、海光信息适配DeepSeek V4的核心技术亮点分别是什么?
答案:各厂商适配技术亮点差异化显著:1. 寒武纪:自研Torch-MLU-Ops算子库,专项加速Compressor、mHC核心模块,vLLM框架支持5D混合并行,释放硬件算力;2. 摩尔线程:MTT S5000原生支持FP8,适配V4“FP4+FP8”混合精度策略,显存带宽压力降低50%;3. 沐曦股份:联合KernelSwift完成算子迁移优化,国产芯片端推理加速3.4倍,算子平均通过率约80%;4. 海光信息:依托自研DTK异构平台+集成2000+算子的DAS系统,全栈深度调优,达成业界领先计算效率。
问题3:DeepSeek V4的发布对国产算力产业链带来哪些影响,存在哪些潜在制约因素?
答案:1. 积极影响:V4的技术突破(超长上下文、低成本)为国产算力提供优质模型适配标的,华为昇腾、寒武纪等厂商完成极速适配,推动芯模协同生态成熟;带动国产AI芯片需求释放,加速产业链商业化落地,提升国产算力全球竞争力。2. 潜在制约因素:一是技术迭代风险,大模型算法优化、国产芯片适配兼容性进度可能不及预期;二是商业化落地风险,行业应用场景渗透不足,难以快速形成规模化营收;三是行业竞争风险,全球大模型厂商密集发新品,价格战或压缩国产算力企业盈利空间。










暂无评论内容