

人工智能产业“十四五”复盘与“十五五”展望:“两个变局”下的AI要素化跃迁
【在线阅读报告】四海报告中搜索 https://report.mklist.com
【迅雷云盘下载】2025.9月报告原文下载:【迅雷云盘】https://pan.xunlei.com/s/VOZ9wFimKIV-NJr2_0dAww72A1?pwd=i6mp#
【夸克网盘下载】2025.9月报告原文下载:【夸克网盘】 https://pan.quark.cn/s/51ad6dae1ed8
1. 一段话总结
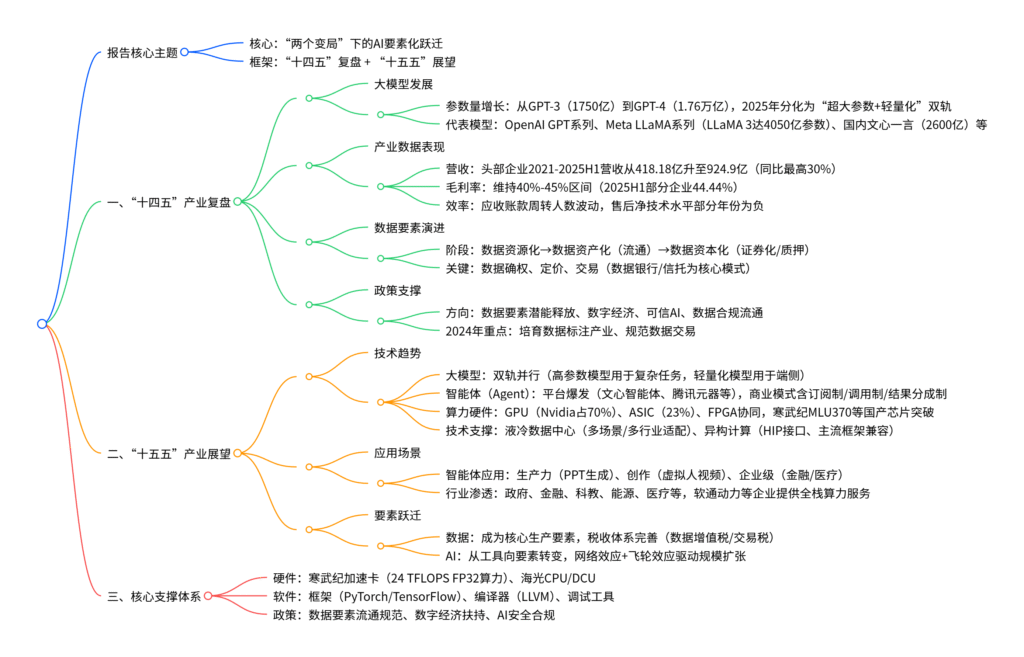
该报告聚焦人工智能产业“十四五”复盘与“十五五”展望,核心围绕“两个变局”下的AI要素化跃迁展开,复盘“十四五”期间AI产业进展:大模型参数量从百亿级跃升至万亿级(如GPT-4达1.76万亿参数),2021-2025H1头部企业营收持续增长(部分企业营收超900亿元,毛利率维持40%以上),数据要素经历“资源化-资产化-资本化”演进;展望“十五五”,AI产业呈现“超大参数模型与轻量化模型并行”“智能体平台爆发”“算力硬件多元化(GPU/ASIC/FPGA协同)” 三大趋势,同时提及政策对数据流通、数字经济的支持,以及液冷数据中心、异构计算等技术对AI产业的支撑,最终指向AI成为核心生产要素的跃迁方向。
2. 思维导图(mindmap)
3. 详细总结
一、报告基础定位
本次报告以“两个变局”下的AI要素化跃迁为核心,系统复盘“十四五”期间人工智能产业在大模型、数据要素、产业营收等维度的进展,同时展望“十五五”技术趋势(大模型双轨化、智能体爆发)、应用场景及要素跃迁方向,为产业发展提供参考。
二、“十四五”人工智能产业复盘
1. 大模型:参数量爆发式增长,2025年开启双轨分化
-
参数量演进:大模型出现前,机器学习算法参数量每5-6年翻1个数量级;大模型落地后增速大幅提升,从2020年GPT-3的1750亿参数,跃升至2023年GPT-4的1.76万亿参数,国内文心一言(2600亿)、DeepSeek等模型同步跟进。
-
2025年分化趋势:大模型正式进入“超大参数模型”与“轻量化模型”并行阶段——超大参数模型(如Meta LLaMA 3的4050亿参数)聚焦复杂任务(逻辑推理、多模态生成),轻量化模型(如7B/13B参数)适配端侧设备(手机、IoT),降低部署成本。
-
主流模型参数对比:
模型 参数量 发布方 GPT-3 1750亿 OpenAI GPT-4 1.76万亿 OpenAI LLaMA 3 80亿、700亿、4050亿 Meta 文心一言(Ernie Bot) 2600亿 百度 PaLM 5400亿 Google
2. 产业营收与盈利:头部企业营收高增,毛利率维持稳定
- 营收表现:2021-2025H1,头部AI企业营收从418.18亿元增长至924.9亿元,年均同比增速最高达30%;细分领域中,部分企业(如智能体平台服务商)2025H1营收达321.81亿元,虽同比略有波动,但整体规模持续扩张。
- 毛利率水平:行业整体毛利率维持在40%-45% 区间,2021-2025H1头部企业毛利率从45.90%微降至44.44%,体现产业盈利稳定性——技术迭代未显著压缩利润,核心源于规模效应与成本控制。
- 运营效率:应收账款周转人数(算数平均)2020-2024年在138-190人区间波动,售后净技术水平部分年份出现负值(如2023年-8%),反映部分企业在客户服务与技术维护环节仍有优化空间。
3. 数据要素:从“资源化”到“资本化”,流通体系逐步完善
-
演进阶段:数据要素经历三阶段跃迁,具体如下:
阶段 核心特征 关键模式 数据资源化 提供方免费供给,需求方免费获取 数据共享、公共数据开放 数据资产化 供需方互利互惠,数据流通有明确规则 数据银行、数据信托、数据交易 数据资本化 引入货币等价物,实现价值变现 数据证券化、数据质押融资 -
政策推动:2024年数字经济领域重点工作明确“释放数据要素潜能”,规范数据确权、定价与流通,培育数据标注产业,为数据资本化奠定基础。
4. 政策与生态:聚焦数字经济,完善产业支撑
- 政策方向:“十四五”期间,政策围绕数字经济、可信AI、数据合规展开,2024年《数字中国建设重点工作》提出“充分发挥标准引导作用,支持可信AI发展”,同时明确公共数据与非公共数据分类流通规则。
- 生态构建:硬件端(寒武纪、海光)、软件端(PyTorch/TensorFlow框架)、应用端(软通动力等IT服务商)形成协同,软通动力通过“软硬一体化”战略,成为全栈算力服务提供商,2022年A股上市后进一步拓展政府、金融等行业场景。
三、“十五五”人工智能产业展望
1. 技术趋势:三大方向引领产业升级
-
大模型双轨化:超大参数模型(4050亿+参数)持续突破复杂任务边界(如科学计算、自动驾驶决策),轻量化模型(7B-13B参数)通过量化、剪枝技术适配端侧,2025年端侧AI模型部署成本预计下降30%。
-
智能体(Agent)爆发:智能体开发平台数量激增,国内已涌现文心智能体平台、腾讯元器KUNLUN、阿里云百炼等超20个平台,覆盖生产力(PPT生成、代码辅助)、创作(虚拟人视频)、企业级(金融风控、医疗问诊)场景;商业模式分为三类:
- 订阅制:用户按周期付费使用(如月度/年度会员);
- 调用制:按API调用量计费(如0.07-1.1美元/百万Token);
- 结果分成制:按智能体创造的价值抽成(如电商智能导购按成交额分成),客单价呈指数级跃升。
-
算力硬件多元化:GPU仍为主流(Nvidia占全球70%市场份额),但ASIC(23%)、FPGA(10.6%)因低功耗、高定制化优势快速渗透——寒武纪AIDC MLU370加速卡提供24 TFLOPS(FP32)训练算力与256 TOPS(INT8)推理算力,支持单机八卡部署,适配多芯多卡训练需求;海光推出x86 CPU与深度计算处理器(DCU),兼容HIP异构编程接口,完善国产算力生态。
2. 应用场景:全行业渗透,智能体成核心载体
- 场景覆盖:智能体深入政府(政务办理助手)、金融(智能投顾)、医疗(问诊助手)、能源(电网调度优化)等领域,飞书智能伙伴、讯飞星辰Agent等平台已接入超3.5万个公开助手,覆盖日常办公、健康管理等核心需求。
- 技术支撑:液冷数据中心成为算力基础设施标配,支持从单柜到大型数据中心的全场景部署(风冷/液冷、机房/户外),软通动力等企业提供“选址-设计-运维”全流程解决方案,降低数据中心PUE至1.2以下。
3. 要素跃迁:AI成为核心生产要素
- 数据要素价值深化:数据交易市场规模预计2027年突破1万亿元,数据税收体系逐步完善(数据增值税、交易税),国有企业数据资产纳入国有资本经营预算,公共数据通过“公开竞标”“直接授权”方式流通,提升使用效率。
- AI要素化效应:AI通过“网络效应+飞轮效应”实现规模扩张——更多用户产生更多数据,推动模型智能提升(网络效应);海量任务分摊固定成本,边际成本趋零,利润再投入研发形成正向循环(飞轮效应),最终实现高额回报。
四、核心支撑体系
1. 硬件支撑:国产芯片与算力设备突破
- 寒武纪MLU370加速卡:双芯配置,提供200GB/s MLU-Link互联带宽(为PCIe4.0的3.1倍),支持FP16/BF16等多精度训练;
- 海光CPU/DCU:兼容x86架构与HIP接口,适配PyTorch/TensorFlow框架,满足异构计算需求;
- 液冷设备:精密空调、换热单元、液冷机柜等产品成熟,覆盖多行业数据中心,降低散热能耗30%以上。
2. 软件支撑:框架与工具链完善
- 主流框架:PyTorch、TensorFlow、MXNet等框架占据主导,国内魔搭社区(Modelscope)提供超1000个开源模型,降低开发门槛;
- 工具链:LLVM编译器、OpenMPI通信库、MIOpen深度学习库形成闭环,支持模型训练、部署与调试全流程,提升开发效率。
五、风险提示
- 技术迭代风险:大模型参数量增长与轻量化需求的平衡难度加大,端侧部署兼容性可能受限;
- 数据合规风险:数据跨境流动、隐私保护政策趋严,可能影响数据要素流通效率;
- 硬件依赖风险:高端GPU仍依赖进口(Nvidia占70%市场份额),国产芯片在算力密度、软件生态上仍有差距。
4. 关键问题
问题1:“十四五”期间大模型参数量实现爆发式增长的核心驱动因素是什么?2025年开启“超大参数+轻量化”双轨分化的底层逻辑是什么?
答案:
(1)大模型参数量爆发的核心驱动因素
① 技术突破:Transformer架构(自注意力机制)解决长序列依赖问题,使模型可高效处理万亿级参数;混合精度训练(FP16/BF16)降低算力消耗,如GPT-4采用BF16精度,较FP32减少50%内存占用;
② 算力支撑:GPU算力密度提升(Nvidia A100达312 TFLOPS FP16算力)、多卡互联技术(PCIe4.0/MLU-Link)实现分布式训练,支持万亿级参数模型落地;
③ 数据供给:互联网数据(Common Crawl、WikiQA)与行业数据(金融、医疗)规模扩张,为大模型提供充足训练素材,如GPT-4训练数据量超10万亿Token。
(2)双轨分化的底层逻辑
① 需求分层:复杂任务(科学计算、多模态生成)需超大参数模型(4050亿+参数)保障精度,端侧任务(手机语音助手、IoT设备)需轻量化模型(7B-13B参数)控制成本与功耗,避免“大材小用”;
② 成本平衡:超大参数模型训练成本超1亿美元(GPT-4训练成本约4.6亿美元),仅适合头部企业;轻量化模型通过量化(FP8)、剪枝技术,部署成本降低60%,适配中小企业与消费端;
③ 场景适配:端侧设备(手机、智能手表)内存/算力有限,7B参数模型可在16GB内存设备上运行,而超大参数模型需数据中心级硬件支撑,无法下沉至端侧。
问题2:“十五五”期间智能体(Agent)爆发的核心商业模式(订阅制/调用制/结果分成制)各有哪些适用场景?不同模式下企业的盈利逻辑与风险点是什么?
答案:
(1)商业模式与适用场景
| 商业模式 | 适用场景 | 典型案例 |
|---|---|---|
| 订阅制 | 高频刚需场景(日常办公、学习辅助) | 飞书智能伙伴(月度会员30元)、讯飞星火助手 |
| 调用制 | 按需使用场景(API接口调用、临时数据处理) | OpenAI GPT-4o(1.25美元/百万Token)、DeepSeek v3 |
| 结果分成制 | 价值共创场景(电商导购、企业降本增效) | 电商智能客服(按成交额1%-3%分成)、工业质检Agent(按不良率降低比例分成) |
(2)盈利逻辑与风险点
-
订阅制:
- 盈利逻辑:通过“低价获客+长期续费”实现稳定现金流,用户留存率(如年留存超60%)是核心指标;
- 风险点:用户付费意愿受场景刚需度影响,若功能迭代缓慢(如仅提供基础文档生成),易出现续费下滑。
-
调用制:
- 盈利逻辑:按调用量阶梯定价(调用量越高单价越低),通过规模效应摊薄服务器成本,适合流量型客户(如互联网企业);
- 风险点:算力成本波动(如GPU价格上涨)可能压缩利润,若调用量不及预期,固定成本(服务器、带宽)压力较大。
-
结果分成制:
- 盈利逻辑:与客户利益绑定,按创造的实际价值抽成(如降本100万元抽成10%-20%),客单价随客户收益增长呈指数级提升;
- 风险点:价值核算难度大(如无法量化智能体对“客户增收”的贡献比例),易引发纠纷;客户业绩波动直接影响分成收入。
问题3:“十四五”至“十五五”期间,数据要素从“资源化”演进至“资本化”的关键障碍是什么?政策与产业层面需采取哪些措施突破这些障碍?
答案:
(1)关键障碍
① 确权难:数据来源复杂(用户生成、企业采集、公共数据),所有权、使用权、收益权界定模糊,如用户社交数据被平台采集后,用户是否拥有收益权尚无明确法律依据;
② 定价难:数据非标准化(如金融风控数据与医疗影像数据价值差异大),缺乏统一估值体系,市场交易多为“一对一议价”,效率低下;
③ 合规难:数据跨境流动(如欧盟GDPR、中国《数据出境安全评估办法》)、隐私保护(如个人信息脱敏)要求严格,部分敏感数据(政务数据、医疗数据)难以流通;
④ 信任难:数据交易中存在“数据篡改”“重复交易”风险,缺乏可信存证机制,买方对数据质量(准确性、完整性)存疑。
(2)突破措施
- 政策层面:
① 完善法律体系:明确数据分类确权规则(如公共数据归国家所有、企业数据归企业所有),2025年前出台《数据产权法》;
② 建立定价标准:推出“数据价值评估指南”,从数据规模、时效性、应用场景三个维度量化价值,如金融高频交易数据定价高于普通消费数据;
③ 规范流通渠道:设立国家级数据交易所(如上海数据交易所、北京国际大数据交易所),实行“备案制+监管沙盒”,确保数据合规流通。 - 产业层面:
① 技术赋能:利用区块链实现数据存证(如蚂蚁链、长安链),记录数据交易全流程,防止篡改;通过联邦学习(Federated Learning)实现“数据可用不可见”,解决隐私保护与流通矛盾;
② 生态构建:培育数据服务商(如数据标注、清洗、估值企业),提升数据质量;推动“数据信托”模式,由第三方机构管理数据,平衡供需方利益(如深圳数据信托试点)。









暂无评论内容